The other day, I came across a really basic fact, which I should have known a long time ago: the empirical median is approximately distributed as a Gaussian in the large-data limit ! Let me share the proof with you: hopefully this will make me remember both the proof and the theorem in the future.
Let’s start by stating the theorem. Let 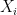 be
be 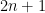 IID random variables, and let
IID random variables, and let 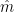 be their empirical median (note that since we have an odd number of datapoints, the empirical is straightforward to find: just order the and find the value at index
be their empirical median (note that since we have an odd number of datapoints, the empirical is straightforward to find: just order the and find the value at index 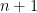 in the ordered list). The theorem states that, in the limit of a large dataset
in the ordered list). The theorem states that, in the limit of a large dataset  , the empirical median has a Gaussian distribution. Even better: we can know exactly what kind of random variable it is: it corresponds to a Beta distribution with parameters
, the empirical median has a Gaussian distribution. Even better: we can know exactly what kind of random variable it is: it corresponds to a Beta distribution with parameters 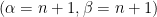 deformed by the inverse of the CDF of the :
deformed by the inverse of the CDF of the :

In order to prove this result, let’s first focus on the case in which the are uniform random variables. Let’s compute the probability 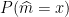 . We have possibilities for the index of the median. Thus, we can focus on the case in which
. We have possibilities for the index of the median. Thus, we can focus on the case in which 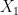 is the median:
is the median:
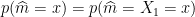
We then need to worry about the other indexes.  points need to be above
points need to be above  and need to below. This gives
and need to below. This gives 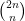 possible repartitions. We can once more focus on a single possibility:
possible repartitions. We can once more focus on a single possibility:  are below and
are below and 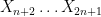 are above.
are above.

Finally, all the are IID independent random variables. The probability above is thus straightforward to compute:
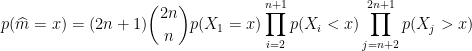
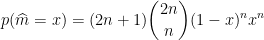

which we recognize as a beta distribution with parameters .
Ok. Now we know what happens for uniform distributions. How can we extend that result to the general case? In order to do so, we have to remember that any random variable can be constructed from a uniform distribution using the inverse of its CDF. Thus, we can construct the as:

Furthermore, the function  is monotonous. Thus, the median of the is the image of the median of
is monotonous. Thus, the median of the is the image of the median of 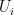 . Since the median of the has a Beta distribution, this means that the median of the has a deformed Beta distribution:
. Since the median of the has a Beta distribution, this means that the median of the has a deformed Beta distribution:
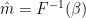
You might notice that we haven’t talked about Gaussians yet, but we’re almost there. Beta distributions become Gaussian with variance tending to 0 in the limit 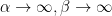 while the ratio
while the ratio 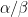 stays constant. This is what happens here when . We have thus proved that in the uniform case, the median becomes Gaussian. Furthermore, because the variance of the Beta also goes to 0 as grows, the non-linear function becomes close to linear and the median becomes close to Gaussian.
stays constant. This is what happens here when . We have thus proved that in the uniform case, the median becomes Gaussian. Furthermore, because the variance of the Beta also goes to 0 as grows, the non-linear function becomes close to linear and the median becomes close to Gaussian.
Note that this property holds in general for all empirical quantiles of IID datapoints. Would you be able to prove it? You just have to slightly modify the steps which I have presented here.
